本系列是南京大学蒋炎岩老师的操作系统课程学习笔记
课程主页:老师的wiki
课程视频:B站合集
第二个MiniLab是实现一个协程库,这个实验确实花了我很长时间,不过也托它的福我对函数调用和线程执行的理解加深了不少,下面分别记录一下这些部分的实现
结构体与变量定义
结构体的定义我直接使用了与wiki相同的,然后根据测试用例的限制定义了一些最大值,整体使用一个数组来管理所有的协程
#define STACK_SIZE 32 / sizeof(uint8_t) * 1024
#define CO_SIZE 128
enum co_status {
CO_NEW = 1, // 新创建,还未执行过
CO_RUNNING, // 已经执行过
CO_WAITING, // 在 co_wait 上等待
CO_DEAD, // 已经结束,但还未释放资源
};
struct co {
char name[20];
void (*func)(void *); // co_start 指定的入口地址和参数
void *arg;
enum co_status status; // 协程的状态
struct co * waiter; // 是否有其他协程在等待当前协程
jmp_buf context; // 寄存器现场 (setjmp.h)
uint8_t stack[STACK_SIZE]; // 协程的堆栈
};
struct co *current // 当前运行的协程;
struct co *co_list[CO_SIZE] // 所有协程的数组;
int co_num // 当前协程数;
这里有个有意思的地方,本来这个char name[20]的数字是我随手写的,后来偶然发现改成30居然就会Segmentation fault,用gdb调试一下就会发现,这就是wiki上提过的堆栈没有按16字节对齐导致的问题
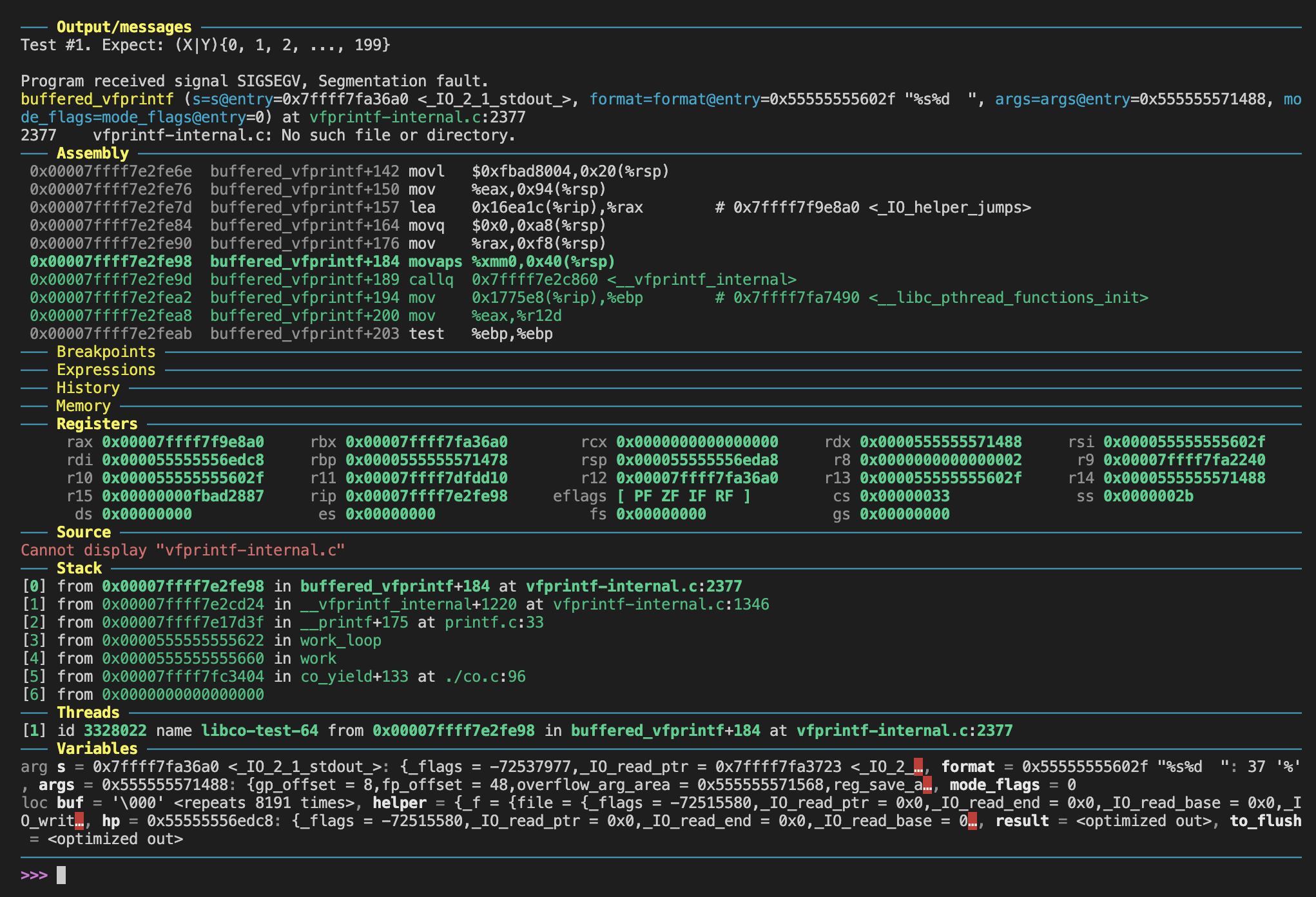
在网上找到了一个解决办法:需要在stack[STACK_SIZE]这句后面加上__attribute__((aligned(16)))就可以让gcc自动帮我们进行16字节对齐了
初始化
由于主线程也是一个协程,所以在初始化时为它分配内存以及设置状态,另外也进行了co_list, co_num, current等相关的初始化
__attribute__((constructor)) void init() {
struct co* main = (struct co*)malloc(sizeof(struct co));
strcpy(main->name, "main");
main->status = CO_RUNNING;
main->waiter = NULL;
current = main;
co_num = 1;
memset(co_list, 0, sizeof(co_list));
co_list[0] = main;
}
co_start
co_start较为简单,只要分配相应的资源即可,为了方便管理需要同步更新co_num和co_list
struct co *co_start(const char *name, void (*func)(void *), void *arg) {
struct co* res = (struct co*)malloc(sizeof(struct co));
strcpy(res->name, name);
res->func = func;
res->arg = arg;
res->status = CO_NEW;
res->waiter = NULL;
assert(co_num < CO_SIZE);
co_list[co_num++] = res;
return res;
}
co_yield
co_yield应该说是整个实验的精髓,也是最容易出错的地方了。根据实验指导书的提示,我们使用setjmp/longjmp来进行协程间的切换
伪代码
co_yield的伪代码如下:
void co_yield() {
int val = setjmp(current->context);
if (val == 0) {
// 选择一个协程执行
} else {
// 从其他协程longjmp过来的,不需要处理
}
}
这里用一个变量current来记录当前运行的协程,类似操作系统中当前进程的概念。假设当前协程为A,当它调用co_yield时,先用setjmp保存A的上下文,然后选择一个协程执行。注意这里要通过setjmp的返回值来进行区分,因为将来A再次被选中执行时,它会通过longjmp从当前位置继续执行,但此时返回值不为0。对于longjmp回来的情况,我们就直接从co_yield返回让协程A继续到调用co_yield的地方执行即可
选择协程执行
选择协程执行的过程如下:
- 用一个函数
get_next_co随机挑选出一个协程 - 如果选择的协程还没执行过,就切换到它的栈执行
- 如果选择的协程已经执行过,说明它调用了
co_yield保存过上下文,那么就调用longjmp恢复它的上下文
我的选择协程函数是从当前为CO_NEW和CO_RUNNING的协程中随机选出一个执行,代码也比较直观
struct co *get_next_co() {
int count = 0;
for (int i = 0; i < co_num; ++i) {
assert(co_list[i]);
if (co_list[i]->status == CO_NEW || co_list[i]->status == CO_RUNNING) {
++count;
}
}
int id = rand() % count, i = 0;
for (i = 0; i < co_num; ++i) {
if (co_list[i]->status == CO_NEW || co_list[i]->status == CO_RUNNING) {
if (id == 0) {
break;
}
--id;
}
}
return co_list[i];
}
执行协程的大致代码如下:
struct co *next = get_next_co();
current = next;
if (next->status == CO_NEW) {
next->status = CO_RUNNING;
// 切换栈运行
next->status = CO_DEAD;
if (current->waiter) {
current = current->waiter;
longjmp(current->context, 1);
}
co_yield();
} else if (next->status == CO_RUNNING) {
longjmp(next->context, 1);
} else {
assert(0);
}
这里最重要的就是如何切换协程的栈,一开始我直接使用wiki上的SWITCH_STACK_CALL的实现,发现在某个协程执行完之后就会发生段错误。因为这个实现使用的是jmp指令,不需要返回,而我们的协程库在某个协程执行完后是需要继续执行其他协程的,所以我们需要用call指令。按照这种方法写出来的切换代码如下:
asm volatile(
#if __x86_64__
"movq %0, %%rsp; movq %2, %%rdi; call *%1"
:
: "b"((uintptr_t)(next->stack + sizeof(next->stack))), "d"(next->func), "a"((uintptr_t)(next->arg))
: "memory"
#else
"movl %0, %%esp; movl %2, (%0); call *%1"
:
: "b"((uintptr_t)(next->stack + sizeof(next->stack) - 8)), "d"(next->func), "a"((uintptr_t)(next->arg))
: "memory"
#endif
);
但运行后还是会发生段错误,使用gdb调试会发现,此时next的值已经明显发生异常,没有指向任何一个实际的协程
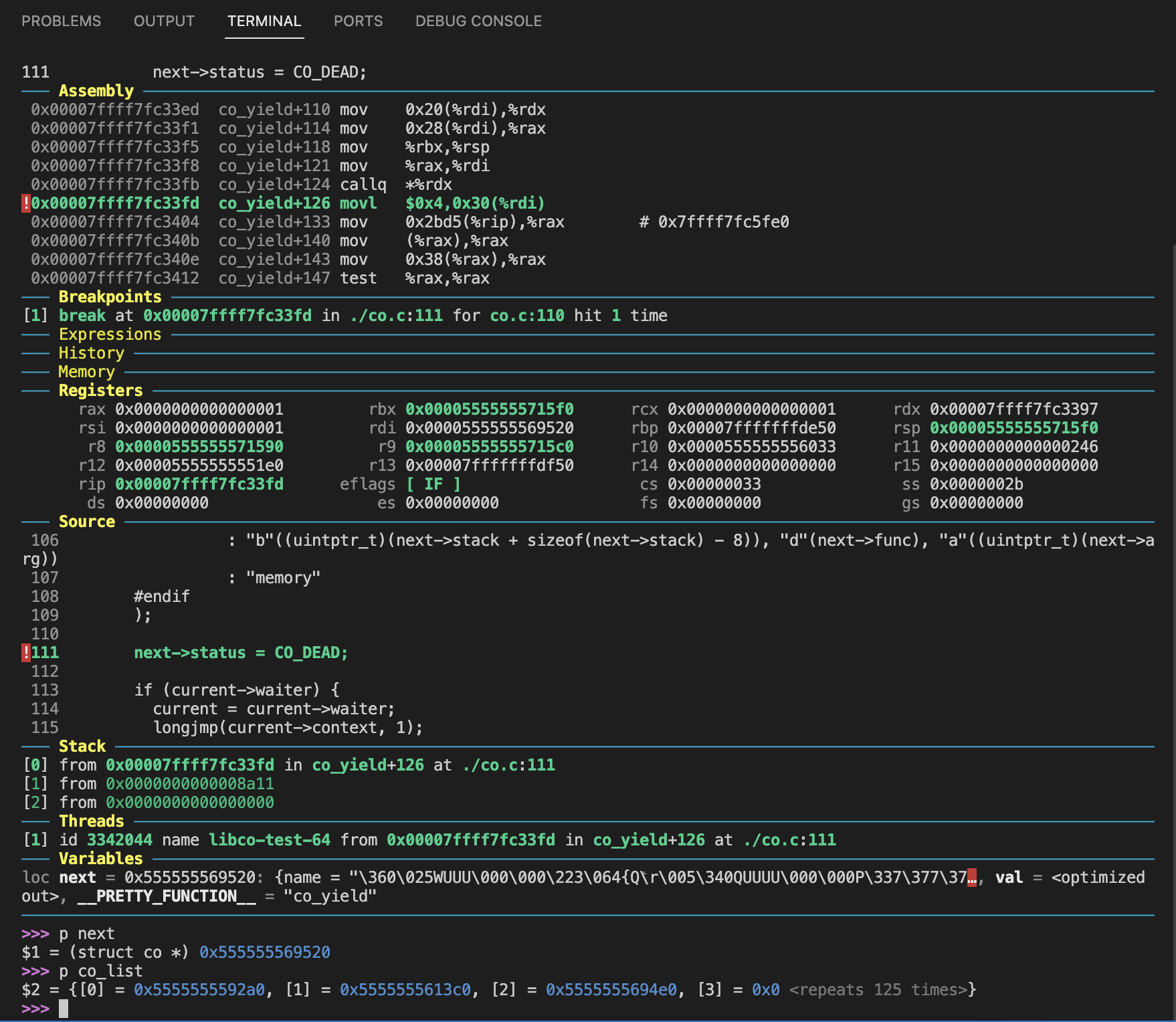
仔细观察生成的co_yield的汇编代码:
000000000000137f <co_yield>:
// 调用setjmp
137f: f3 0f 1e fa endbr64
1383: 53 push %rbx
1384: 48 8b 05 55 2c 00 00 mov 0x2c55(%rip),%rax # 3fe0 <current@@Base-0xc8>
138b: 48 8b 38 mov (%rax),%rdi
138e: 48 83 c7 40 add $0x40,%rdi
1392: e8 69 fd ff ff callq 1100 <_setjmp@plt>
1397: f3 0f 1e fa endbr64
// 判断val的值
139b: 85 c0 test %eax,%eax
// 不为0就直接返回
139d: 74 02 je 13a1 <co_yield+0x22>
139f: 5b pop %rbx
13a0: c3 retq
// 为0,调用get_next_co
13a1: e8 6a fd ff ff callq 1110 <get_next_co@plt>
// rax为返回值,所以这里是将next存在rdi寄存器(重要)
13a6: 48 89 c7 mov %rax,%rdi
// 将next赋值给current
13a9: 48 8b 05 30 2c 00 00 mov 0x2c30(%rip),%rax # 3fe0 <current@@Base-0xc8>
// 读取next的status
13b0: 48 89 38 mov %rdi,(%rax)
13b3: 8b 47 30 mov 0x30(%rdi),%eax
// 判断status的值进行跳转
13b6: 83 f8 01 cmp $0x1,%eax
13b9: 74 24 je 13df <co_yield+0x60>
13bb: 83 f8 02 cmp $0x2,%eax
13be: 74 7e je 143e <co_yield+0xbf>
// assert(0)的地方
13c0: 48 8d 0d 69 0c 00 00 lea 0xc69(%rip),%rcx # 2030 <__PRETTY_FUNCTION__.2826>
13c7: ba 79 00 00 00 mov $0x79,%edx
13cc: 48 8d 35 2d 0c 00 00 lea 0xc2d(%rip),%rsi # 2000 <_fini+0xa68>
13d3: 48 8d 3d 49 0c 00 00 lea 0xc49(%rip),%rdi # 2023 <_fini+0xa8b>
13da: e8 11 fd ff ff callq 10f0 <__assert_fail@plt>
// 设置status为CO_RUNNING
13df: c7 47 30 02 00 00 00 movl $0x2,0x30(%rdi)
// 切换栈的实现
13e6: 48 8d 9f 10 81 00 00 lea 0x8110(%rdi),%rbx
13ed: 48 8b 57 20 mov 0x20(%rdi),%rdx
13f1: 48 8b 47 28 mov 0x28(%rdi),%rax
13f5: 48 89 dc mov %rbx,%rsp
13f8: 48 89 c7 mov %rax,%rdi
13fb: ff d2 callq *%rdx
// 设置status为CO_DEAD
13fd: c7 47 30 04 00 00 00 movl $0x4,0x30(%rdi)
// 剩余的代码
1404: 48 8b 05 d5 2b 00 00 mov 0x2bd5(%rip),%rax # 3fe0 <current@@Base-0xc8>
140b: 48 8b 00 mov (%rax),%rax
140e: 48 8b 40 38 mov 0x38(%rax),%rax
1412: 48 85 c0 test %rax,%rax
1415: 75 0f jne 1426 <co_yield+0xa7>
1417: b8 00 00 00 00 mov $0x0,%eax
141c: e8 5e ff ff ff callq 137f <co_yield>
1421: e9 79 ff ff ff jmpq 139f <co_yield+0x20>
1426: 48 8b 15 b3 2b 00 00 mov 0x2bb3(%rip),%rdx # 3fe0 <current@@Base-0xc8>
142d: 48 89 02 mov %rax,(%rdx)
1430: 48 8d 78 40 lea 0x40(%rax),%rdi
1434: be 01 00 00 00 mov $0x1,%esi
1439: e8 02 fd ff ff callq 1140 <longjmp@plt>
143e: 48 83 c7 40 add $0x40,%rdi
1442: be 01 00 00 00 mov $0x1,%esi
1447: e8 f4 fc ff ff callq 1140 <longjmp@plt>
在13fd处next的内存已经被破坏,它的值是被存放在rdi寄存器的,而我们切换栈时用到了这个寄存器,所以执行完后寄存器里的值就不再是next的地址了。因此需要在切换的时候保存rdi寄存器的值,执行完再进行恢复。对于32位程序也是一样,只不过要保存的现场更多一些,就不详细再讲了
asm volatile(
#if __x86_64__
"movq %%rdi, (%0); movq %0, %%rsp; movq %2, %%rdi; call *%1"
:
: "b"((uintptr_t)(next->stack + sizeof(next->stack))), "d"(next->func), "a"((uintptr_t)(next->arg))
: "memory"
#else
"movl %%esp, 0x8(%0); movl %%ecx, 0x4(%0); movl %0, %%esp; movl %2, (%0); call *%1"
:
: "b"((uintptr_t)(next->stack + sizeof(next->stack) - 8)), "d"(next->func), "a"((uintptr_t)(next->arg))
: "memory"
#endif
);
asm volatile(
#if __x86_64__
"movq (%0), %%rdi"
:
: "b"((uintptr_t)(next->stack + sizeof(next->stack)))
: "memory"
#else
"movl 0x8(%0), %%esp; movl 0x4(%0), %%ecx"
:
: "b"((uintptr_t)(next->stack + sizeof(next->stack) - 8))
: "memory"
#endif
);
co_wait
co_wait也比较简单,如果要等待的协程没有结束,就一直co_yield,当它结束后就回收相应的资源。这也是为什么当某个协程执行结束后(运行完切换栈的代码,status变成CO_DEAD)要将当前协程转为等待它的协程,就是为了让等待的协程有机会运行。这里我将结束的协程从列表移除后将其他协程整体前移了
void co_wait(struct co *co) {
assert(co != NULL);
co->waiter = current;
current->status = CO_WAITING;
while (co->status != CO_DEAD) {
co_yield();
}
free(co);
int id = 0;
for (id = 0; id < co_num; ++id) {
if (co_list[id] == co) {
break;
}
}
while (id < co_num - 1) {
co_list[id] = co_list[id+1];
++id;
}
--co_num;
co_list[co_num] = NULL;
}
总结
这个实验终点就在于需要理解函数、栈、协程之间的关系
- 通常情况下,栈由一个个连续的栈帧组成,每个栈帧有一个相应的栈底,用
rbp寄存器表示,当使用gdb调试时可以用f x切换到x号栈帧来查看当前栈帧的各寄存器的状态,栈顶存放的就是下一个栈帧释放时rip寄存器应该跳转的地址 - 每个栈帧对应的就是一次函数调用,
64位程序和32位程序有相应的calling convention来约定参数的传递方式——通过寄存器或是通过栈 - 当为协程切换栈时,我们其实是将连续的栈帧分散到了不同的内存区域。本来栈应该由地址空间的栈顶向下生长,为了模拟协程的运行我们将栈指针
rsp指向了堆的某个地址,让它从这里继续生长。用gdb调试就会发现,main协程的调用栈是以7fff开头,而其他协程都是以5555开头
最终运行结果:
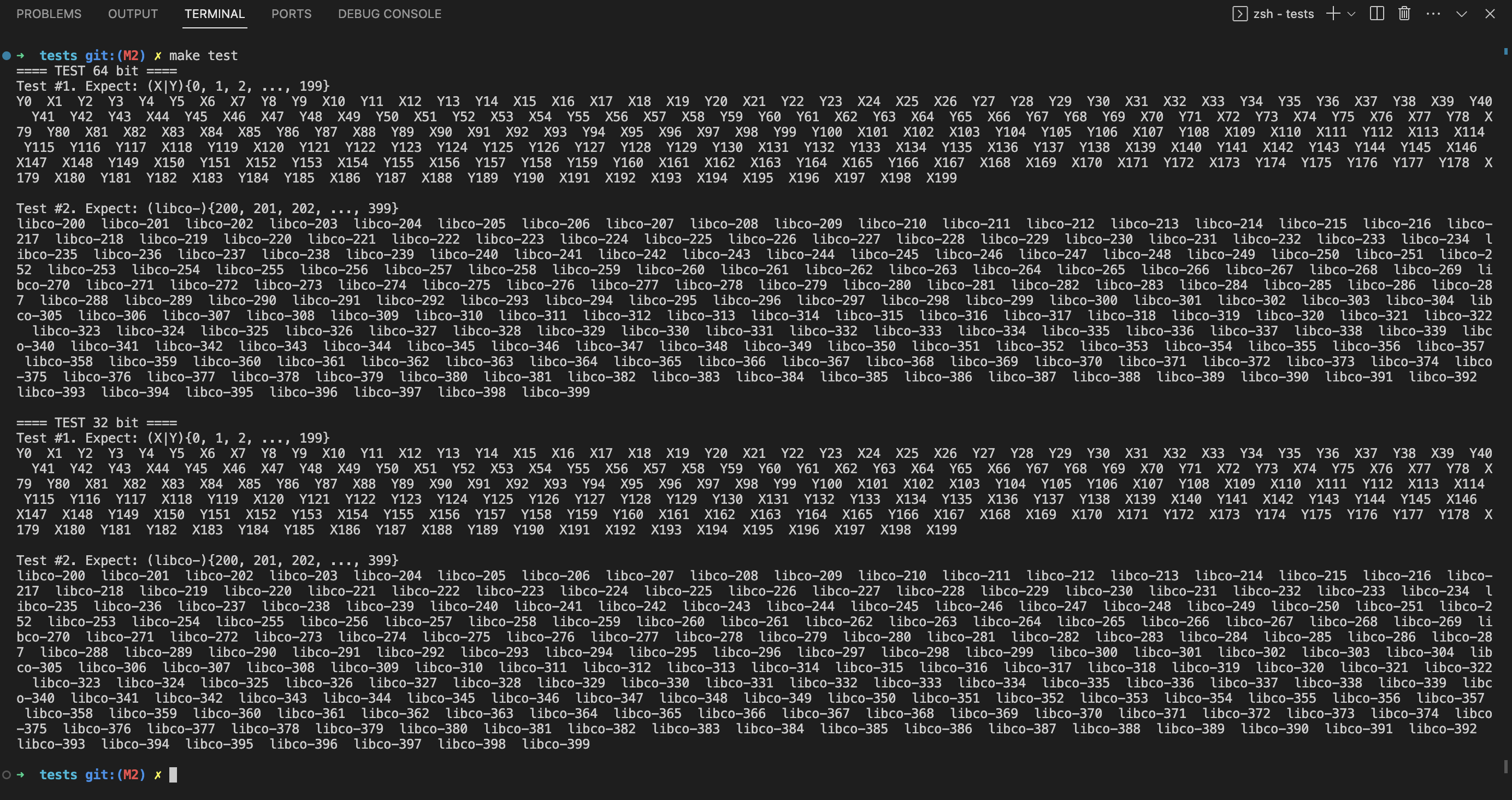
完整代码详见Github仓库