本系列是南京大学蒋炎岩老师的操作系统课程学习笔记
课程主页:老师的wiki
课程视频:B站合集
第一节课回答了一个问题:什么是程序
由于使用的是ssh登录linux机器来学习,这里也记录一下
📌 使用ssh登录linux的方法:ssh username@remote_host,例如:ssh cy@127.0.0.1
数字电路与状态机
首先介绍了什么是状态机,状态机可以理解为数字电路的有限种状态的集合,数字电路的初始值即位状态机的初始状态,状态之间的迁移通过组合逻辑电路来计算出下一个状态 比如有两个寄存器X,Y,初始值均为0,实现的数字电路为:
X = !X && Y
Y = !X && !Y
那么状态机就会经历如下的状态迁移: (0, 0) -> (0, 1) -> (1, 0) -> (0, 0) …
什么是程序(源代码视角)
从源代码的角度来看,程序也是状态机。简单的理解:
- 状态就是程序的堆和栈
- 迁移方式就是每次执行的语句
如果用gdb来调试,我们会更直观的感受到,PC(程序计数器)总是指向某一条语句,执行该语句后则跳转到下一条
📌 设置gdb展示源代码:layout src

更深层次的理解:
- 状态 = 栈帧列表(每个栈帧有对应的PC)+ 全局变量
- 初始状态 = main(argc, argv) + 全局变量初始化
- 状态迁移 = 执行top stack frame的PC对应的语句,PC++
- 函数调用 = push frame (frame.PC = 入口)
- 函数返回 = pop frame
来看一个递归实现的汉诺塔程序,不难理解
#include <stdio.h>
void hanoi(int n, char from, char via, char to) {
if (n == 1) {
printf("%c -> %c\n", from, to);
return;
}
hanoi(n - 1, from, to, via);
hanoi(1, from, via, to);
hanoi(n - 1, via, from, to);
}
int main() {
hanoi(3, 'A', 'B', 'C');
}
// Output
A -> C
A -> B
C -> B
A -> C
B -> A
B -> C
A -> C
当理解了程序是状态机这一原理之后,我们可以通过改变栈帧的方式将其改写为非递归的形式
#include <stdio.h>
typedef struct {
int pc, n;
char from, via, to;
} Frame;
#define call(...) ({ *(++top) = (Frame) {.pc = 0, __VA_ARGS__}; })
// 注意:这里为什么是n - 1?因为for循环内会自动让f->pc++
#define go(n) ({ f->pc = n - 1; })
// 注意:这里需要设置f->pc = 0吗?不需要,因为当前的栈帧都没用了,下次循环时f会指向上一个栈帧,并从该栈帧的pc继续执行
#define ret() ({ --top; })
void hanoi_nr(int n, char from, char via, char to) {
Frame stack[64], *top = stack - 1;
call(n, from, via, to);
for (Frame *f; (f = top) >= stack; f->pc++) {
switch (f->pc) {
case 0:
if (f->n == 1) {
printf("%c -> %c\n", f->from, f->to);
go(4);
}
break;
case 1:
call(f->n - 1, f->from, f->to, f->via);
break;
case 2:
call(1, f->from, f->via, f->to);
break;
case 3:
call(f->n - 1, f->via, f->from, f->to);
break;
case 4:
ret();
break;
}
}
}
int main() { hanoi_nr(3, 'A', 'B', 'C'); }
这段代码其实就是递归的形式,只不过我们将递归的调用改成了操作栈帧和PC的形式。每次递归调用时就创建一个栈帧,根据栈帧内PC的不同值执行对应的语句。这里每个栈帧的大小是一样的,只有两个int和三个char,在一般的程序中,栈帧大小通常跟当前函数的局部变量个数有关,但原理是一样的
什么是程序(二进制视角)
- 状态 = 寄存器R,内存M
- 初始状态 = ?(后续解释)
- 迁移 = 执行一条指令
同样用gdb来观察
📌 使用starti来使gdb执行第一条指令,使用layout asm来使gdb展示汇编代码
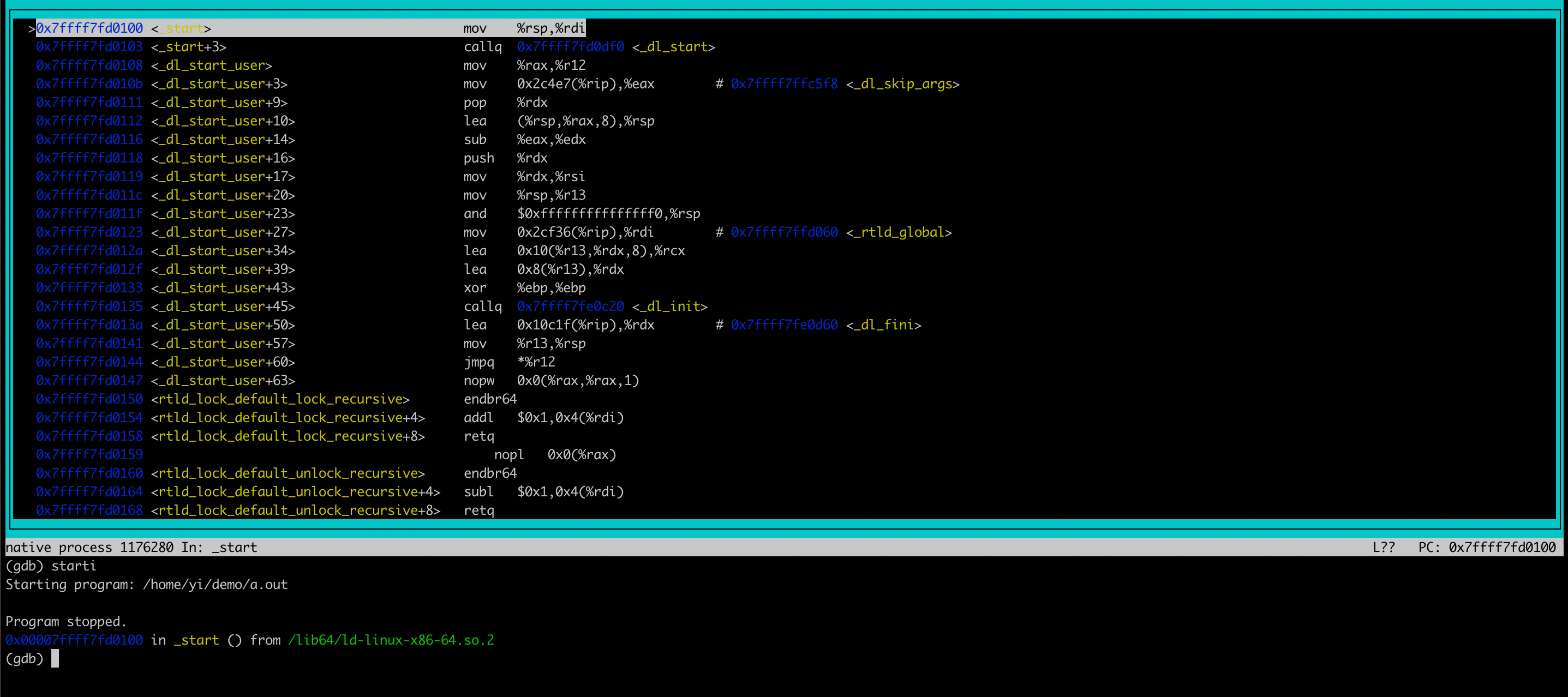 我们可以看到,与源代码不同的是,此时状态机的迁移变成了一条条的汇编指令
我们可以看到,与源代码不同的是,此时状态机的迁移变成了一条条的汇编指令
这里要记住一个事实:所有的指令都只能计算,做不到其他的事情(比如让程序停止运行)
于是就引出了系统调用的概念,系统调用可以看作是一个特殊的指令,程序将自己的状态(R,M)完全交给操作系统随意修改,从而实现与操作系统中其他对象的交互
- 读写文件/操作系统状态(例如将文件内容写回M)
- 改变程序状态(例如退出程序)
因此
程序 = 计算 + syscall
问题:构建一个最小的Hello World程序
Naive approach
#include <stdio.h>
int main() {
printf("Hello, World\n");
}
这个程序是否真的够小呢?当我们使用gcc --verbose查看gcc的完整编译选项时,会发现其实有很多很多的选项。再使用size查看可执行文件的大小,会发现有2000+字节
➜ size a.out
text data bss dec hex filename
1566 600 8 2174 87e a.out
如果我们使用gcc -static静态编译这个程序,会发现大小远远超乎我们的想象
➜ size a.out
text data bss dec hex filename
762417 20804 6016 789237 c0af5 a.out
强行编译+链接
📌 使用gcc -c仅进行编译
 我们会发现,ld找不到库函数,这是当然的,因为我们没有把
我们会发现,ld找不到库函数,这是当然的,因为我们没有把<stdio.h>编译进来,还有一个奇怪的warning说找不到入口_start
那么我们试试不调用库函数,并将main改名为_start
int _start() {
}
这次确实没有报错了,表示已经编译成功了,但当我们运行这个可执行文件时:
[1] 1178117 segmentation fault (core dumped) ./a.out
那么接下来我们用gdb看看为什么会出现段错误,当我们进行单步调试后我们会发现,程序直到执行retq之前都正常,但返回后就崩溃了
 这时需要复习一下函数调用的实现以及
这时需要复习一下函数调用的实现以及retq指令做了什么,我们写一个简单的程序来看一下
📌 使用objdump -d查看程序的汇编代码
void t() {}
void bar() {
int x = 1;
int y = 2;
t();
int z = 3;
int a = 4;
}
void foo() {
bar();
}
// gcc -c test.c && objdump -d test.o
test.o: file format mach-o 64-bit x86-64
Disassembly of section __TEXT,__text:
0000000000000000 <_t>:
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 5d popq %rbp
5: c3 retq
6: 66 2e 0f 1f 84 00 00 00 00 00 nopw %cs:(%rax,%rax)
0000000000000010 <_bar>:
10: 55 pushq %rbp
11: 48 89 e5 movq %rsp, %rbp
14: 48 83 ec 10 subq $16, %rsp
18: c7 45 fc 01 00 00 00 movl $1, -4(%rbp)
1f: c7 45 f8 02 00 00 00 movl $2, -8(%rbp)
26: e8 00 00 00 00 callq 0x2b <_bar+0x1b>
2b: c7 45 f4 03 00 00 00 movl $3, -12(%rbp)
32: c7 45 f0 04 00 00 00 movl $4, -16(%rbp)
39: 48 83 c4 10 addq $16, %rsp
3d: 5d popq %rbp
3e: c3 retq
3f: 90 nop
0000000000000040 <_foo>:
40: 55 pushq %rbp
41: 48 89 e5 movq %rsp, %rbp
44: e8 00 00 00 00 callq 0x49 <_foo+0x9>
49: 5d popq %rbp
4a: c3 retq
函数调用的全过程(注意栈是向下生长的,因此高地址为底部,低地址为顶部)
- 执行
callq指令:此时会将%rip的值入栈,%rip此时指向callq的下一条指令,也就是将来函数调用返回时的地址。然后跳转到对应函数的起始位置 - 将
%rbp入栈:此时%rsp下移8个字节,并在对应位置保存%rbp的值,这是调用函数前的栈底地址 - 将
%rsp的值赋给%rbp,经过这一步后,%rbp会指向新栈的栈底,里面保存着返回上一个栈底地址 - 将
%rsp下移,使其指向新栈的栈顶 - 局部变量入栈,执行函数体
- 将
%rsp上移,使其回到栈底的位置 %rbp出栈:此时先取出%rsp处保存的值(也就是原来的栈底地址),并赋给%rbp,此时%rbp重新指向调用函数前的栈底。然后将%rsp上移8个字节,此时%rsp指向函数返回后的下一条指令- 执行
retq:- 将pc移动到函数返回后的下一条指令
mov (%rsp), rip rsp重新指向调用函数前的栈顶mov rsp, rsp + 8
- 将pc移动到函数返回后的下一条指令
示意图:
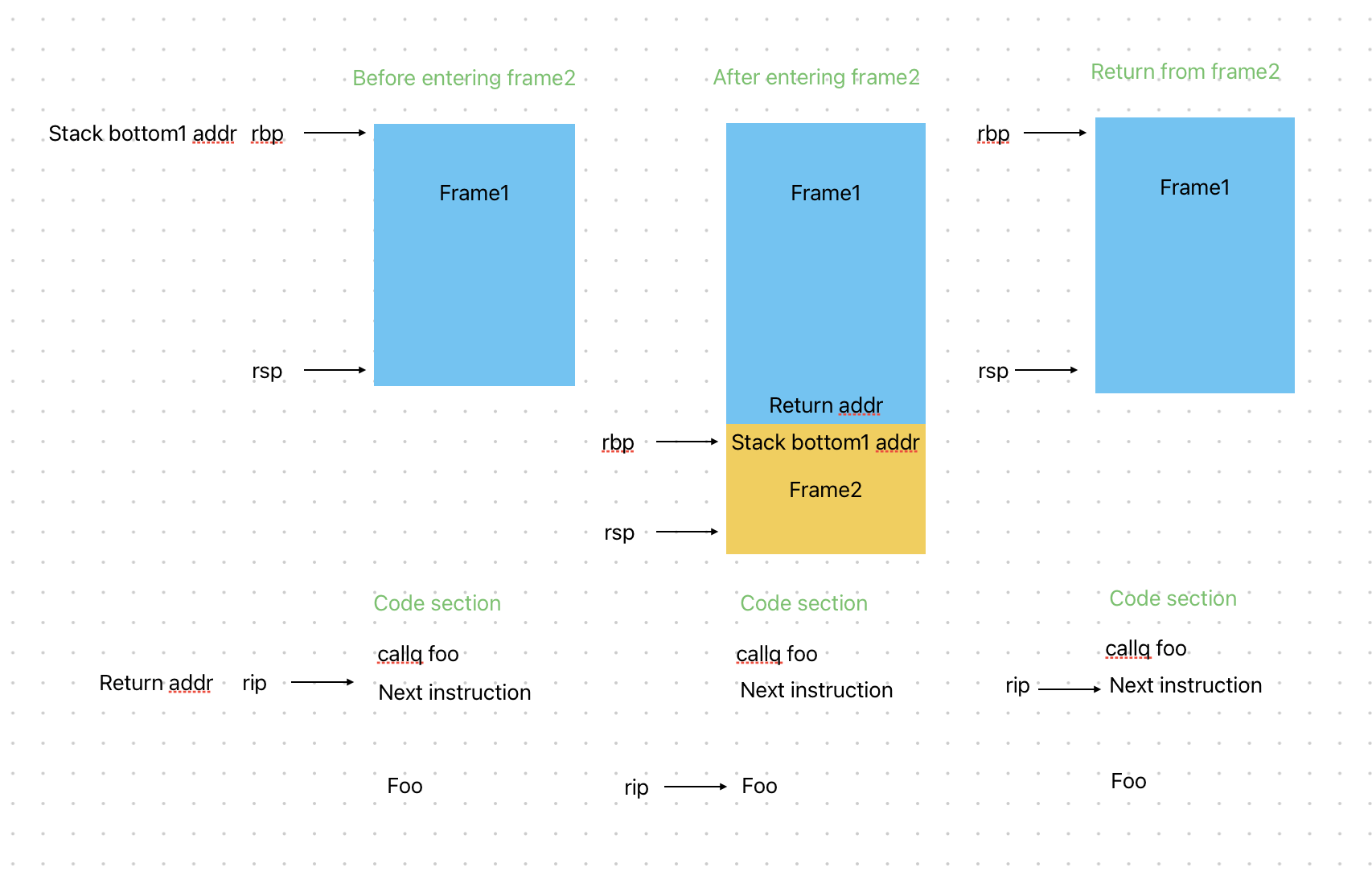 从图中我们还能发现,每个栈帧顶部保存的就是下一个栈帧释放时,
从图中我们还能发现,每个栈帧顶部保存的就是下一个栈帧释放时,%rip要跳转的地址,也即函数的返回地址
回到刚才发生段异常的地方,既然retq出错了,那么要么是取%rsp的时候出错,要么是更新%rsp的值出错,我们可以进一步调试
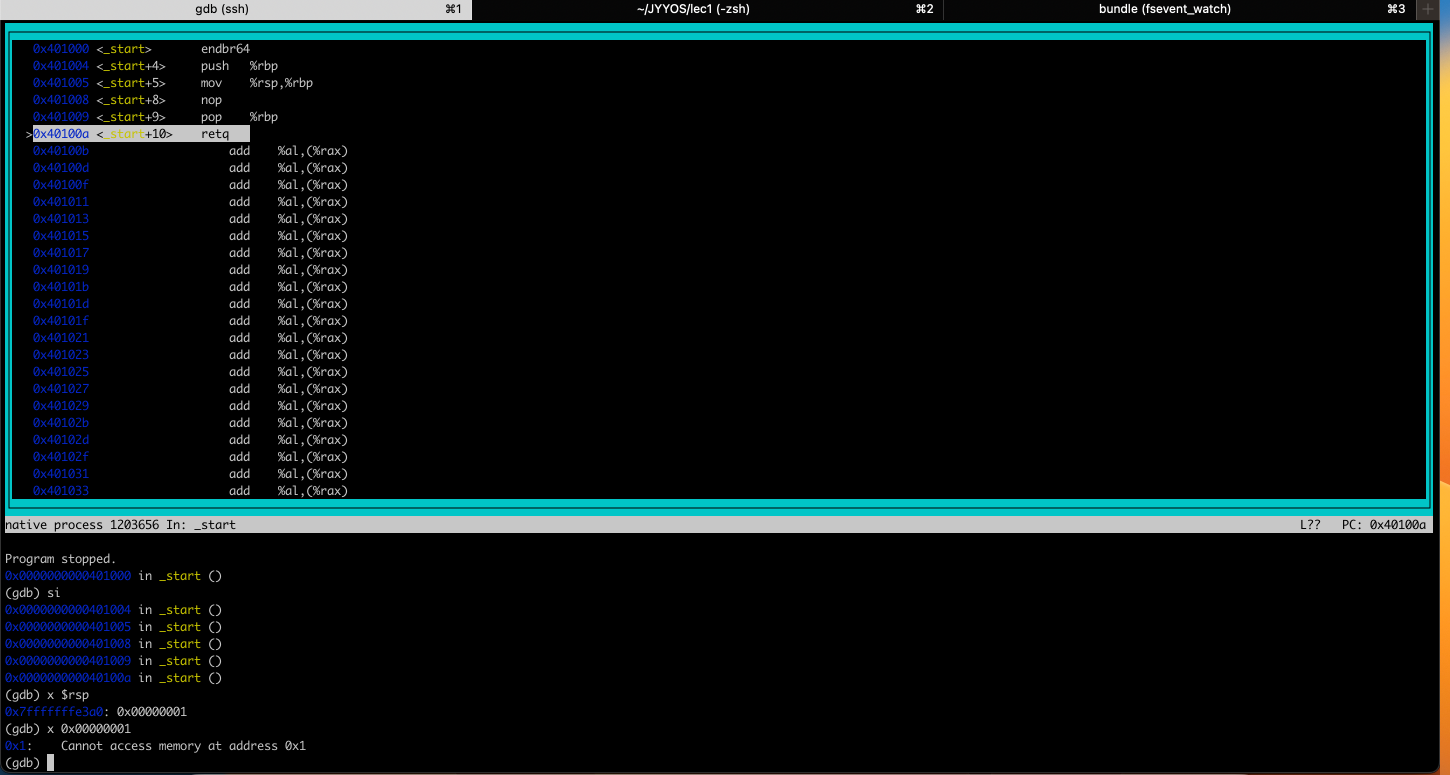 会发现此时
会发现此时%rsp保存的值为0x1,不是一个合法地址,所以retq就会访问异常了,解决方案是使用syscall
syscall
直接上代码
#include <sys/syscall.h>
.global _start
_start:
movq $SYS_write, %rax # write(
movq $1, %rdi # fd = 1,
movq $st, %rsi # buf = st,
movq $(ed - st), %rdx # length = ed - st
syscall # );
movq $SYS_exit, %rax # exit(
movq $1, %rdi # 1
syscall # );
st:
.ascii "\033[31;44mHello, World\n"
ed:
这是一段汇编代码,分别调用了如下两条系统调用:
syscall(SYS_write, 1, "\033[31;44mHello, World\n", strlen("\033[31;44mHello, World\n"));
syscall(SYS_exit, 1);
打印的效果如图

这里的小彩蛋就是用了ANSI Escape Code来控制打印出来的Hello World的样式。同时我们可以看到这个程序是很小的
➜ size a.out
text data bss dec hex filename
67 0 0 67 43 a.out
如何在两个视角间切换
使用编译器。编译器就是自动将源代码转化成汇编代码的工具
// C = Assemble code
// S = Source code
C = Compiler(S)
何谓正确的编译器呢?保证S和C的行为完全一致。
如果一个编译器完全按照源代码进行解释性编译,那么其语义一定与源代码相同。但现代编译器都具备优化功能,会进行大量的优化,例如指令重排,删除不必要的指令等等
操作系统中的一般程序
所有程序与前述的最小的Hello World程序本质都是一样的,等于计算+系统调用。操作系统管理了所有的软硬件资源,对程序来说操作系统就是一个接口,程序可以从中拿各种信息,也可以请求完成一些操作
程序也是操作系统中的对象,与文本文件本质相同,只不过是二进制的,vim无法正确显示,xxd可以看到
如何得知程序的初始状态?使用gdb
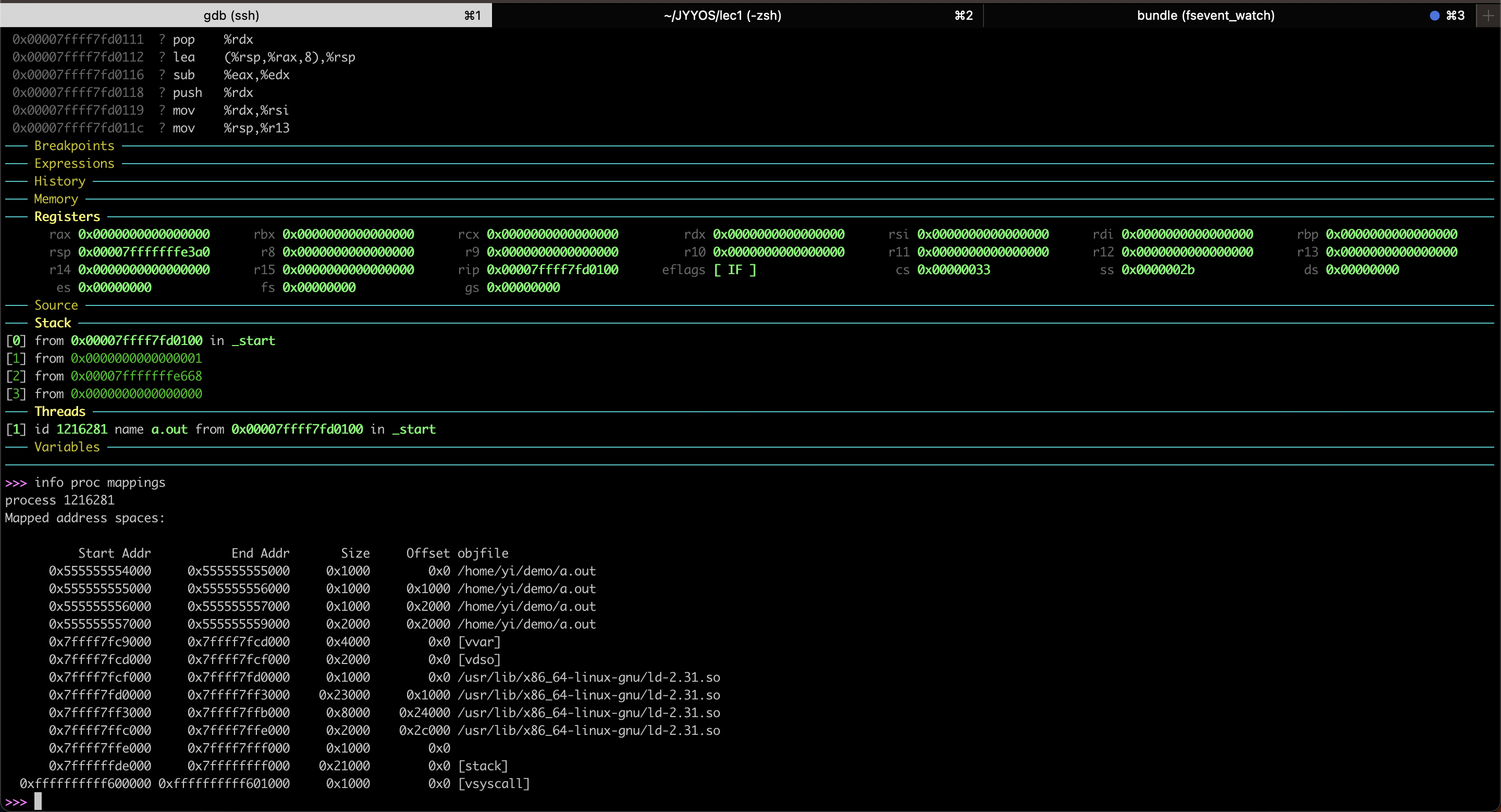
从图中能看到,第一条指令位于0x00007ffff7fd0100,其实是linux的加载器。高地址区域都是操作系统映射的,而低地址区则是程序本身的空间
既然程序的运行过程有着确定的机制,那么我们就可以用相应的工具来进行观测。strace可以打印出一个程序使用的所有系统调用
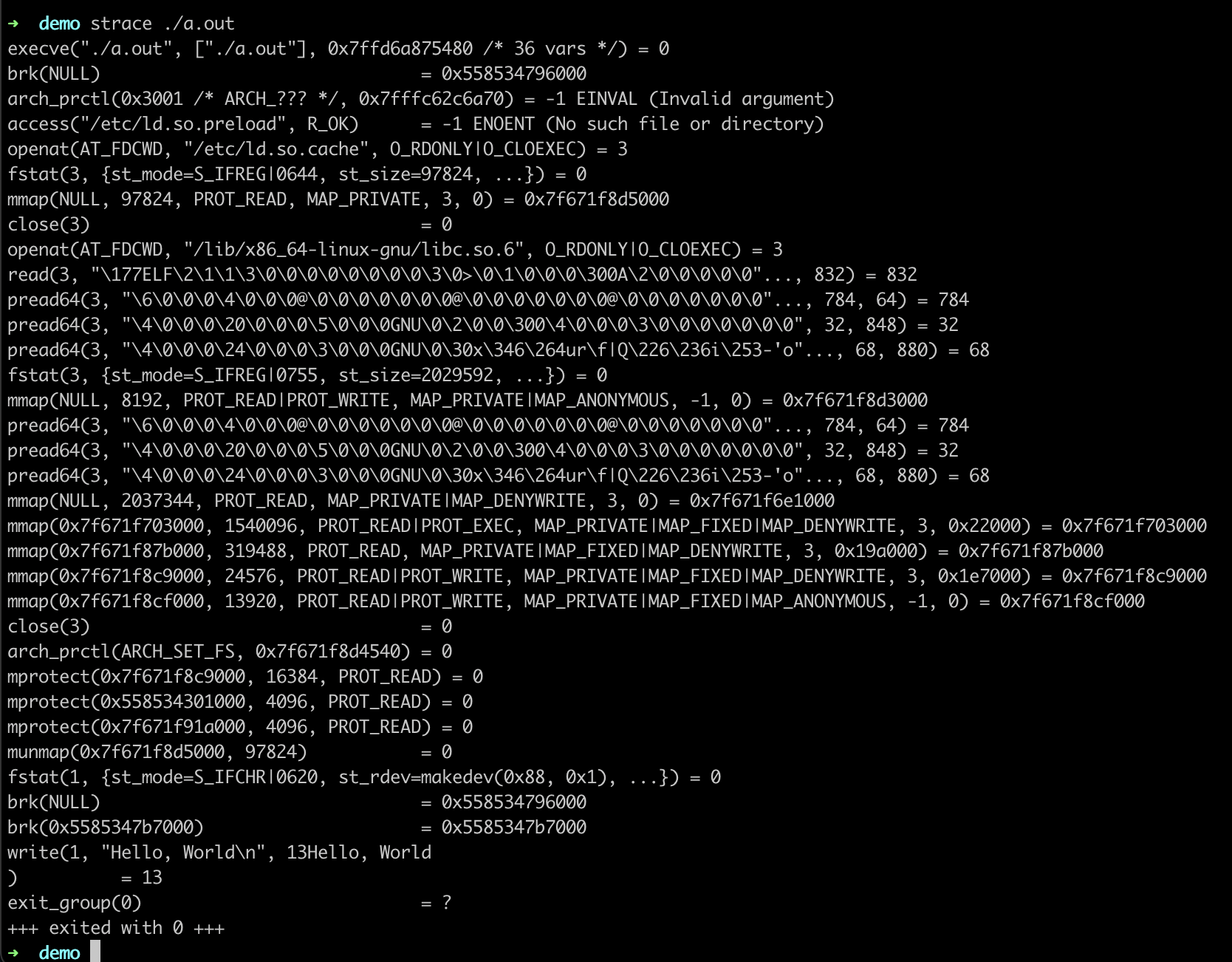
可以看到每个程序执行的第一条系统调用一定是exec